
結婚のお礼と報告 でちょこっと書いた結婚式エンドロールをその場で作ってみたのお話
注意事項
結婚式のエンドロールを自作したりするには結婚式場の協力が必須です。
作り出す前に式場に必ず確認を取りましょう。
PCからそのままプロジェクトにだせばいいじゃん!と思い込むのだめです(自戒)
動機
エンドロールを式場にお願いしようと思ったら高かったので、最近のイケてるサービスとか適当にガッチャンコすれば作れると思った。 今は反省している。
全体の構成
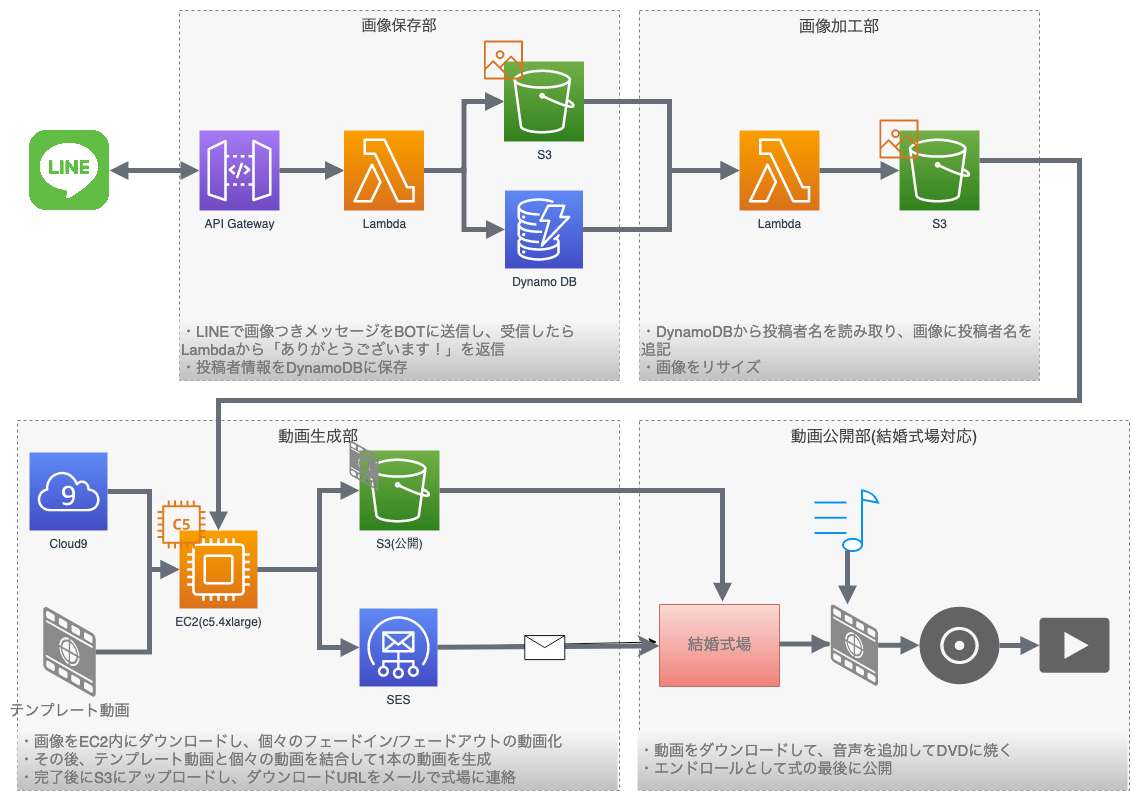
- LINE Botに参加者から画像投稿を投げてもらう
- S3に保存すると同時に投稿者情報をDynamoDBに保存
- 投稿された画像にDynamoDBの投稿者情報から名前を追記
- 画像を全部結合して動画化し、事前に生成したエンドロールで必要な部分を結合
- 式の最後に流してもらう
全体の構成はこんな感じです。
サーバーレスアーキテクチャのお勉強がてら作ろうとしたので、EC2を使わないようにしたのですが、最終的にはそうもいきませんでした…
基本的コードはPython3で書いてます。
細かい部分は以下を参照
画像保存部分
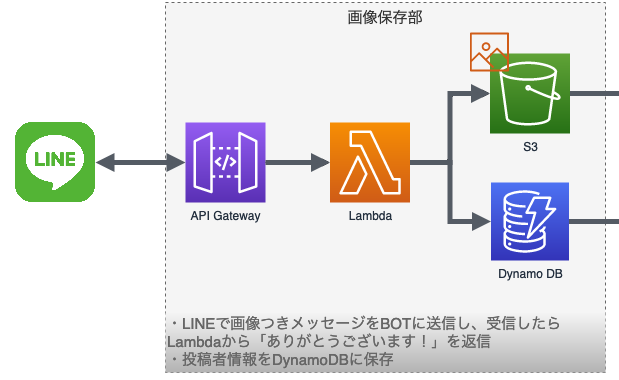
LINE developers サイトのMessaging APIとaws Lambda、API Gatewayの組み合わせでこのあたりはサクッと出来上がりました。
本来は画像保存と加工は同時にやって、S3バケットも1つにしたほうがスマートな感じですが、事故防止とS3イベントでのLambdaも触ってみたかったのであえて加工部分と分離しました。
そのためにDynamoDBに投稿者情報を保存してるのは本末転倒感ありますが…
LINEのチャンネルアイコンは妻にお願いして書いてもらいました。
このあたりは共同作業です。
Lambdaコード
import requests
import os
import json
import boto3
import logging
from PIL import Image
from io import BytesIO
# Log設定
LOGGER = logging.getLogger()
LOGGER.setLevel(logging.INFO)
# Headerの生成
HEADER = {
"Content-type":"application/json",
"Authorization": "Bearer " + os.environ["LINE_CHANNEL_ACCESS_TOKEN"]
}
# タイプ
# 0:test
# 1:本番?
# 2:でも?
# 3:TEST01
TYPE = 1
# S3 Bucket名
BUCKET_NAME = "BUCKET_NAME-row"
# S3フォルダ名
FOLDER_NAME = ["TEST01", "wedding", "dev1", "develop"]
# dynamoDB テーブル名
DYNAMODB_TABLE_NAME = "DYNAMODB_TABLE_NAME"
# 管理者ID
ADMIN_ID = os.environ["ADMIN_ID"]
#main
def lambda_handler(event, context):
LOGGER.info(event)
#Json Load
body = json.loads(event["body"])
for event in body["events"]:
# 投稿ユーザー名取得
user_name = get_user_name(event["source"]["userId"])
# ImageMessageが来た時
if event["message"]["type"] == "image":
# メッセージID取得
message_id = event["message"]["id"]
# Imagecontent取得
image_file = requests.get("https://api-data.line.me/v2/bot/message/" + message_id +"/content",headers=HEADER)
# 画像取得
image_bin = BytesIO(image_file.content)
image = image_bin.getvalue()
img = Image.open(image_bin)
img_size = img.size
# S3へのアップロード
s3 = boto3.client("s3")
file_name = FOLDER_NAME[TYPE] + "/" + message_id + ".jpeg" # メッセージID+jpegをファイル名
# s3へのput処理
put_s3_response = s3.put_object(
Bucket=BUCKET_NAME,
Body=image, # 写真
Key=file_name # ファイル名
)
LOGGER.info(put_s3_response)
# MEAT情報をdynamodbに登録
dynamoDB = boto3.resource("dynamodb")
table = dynamoDB.Table(DYNAMODB_TABLE_NAME)
put_dynamodb_response = table.put_item(
Item = {
"filename": file_name,
"username": user_name,
"timestamp": event["timestamp"],
"type": TYPE,
"width": img_size[0],
"height": img_size[1]
}
)
LOGGER.info(put_dynamodb_response)
# 返信
return_msg = user_name + "さん、ありがとうございます!!"
result = send_line_replay_message(event["replyToken"], return_msg)
# textnesseageが来たとき
elif event["message"]["type"] == "text":
if event["message"]["text"] == "動画作成" and event["source"]["userId"] == ADMIN_ID:
else:
# 返信
return_msg = user_name + "さん、ありがとうございます!!" + event["message"]["text"]
result = send_line_replay_message(event["replyToken"], return_msg)
def send_line_replay_message(replyToken, message):
PAYLOAD = {
"replyToken":replyToken,
"messages":[
{
"type":"text",
"text": message
}
]
}
response = requests.post(
"https://api.line.me/v2/bot/message/reply",
headers=HEADER,
data=json.dumps(PAYLOAD)
)
LOGGER.info(response.json())
return response
def get_user_name(user_id):
user_name = requests.get("https://api.line.me/v2/bot/profile/" + user_id ,headers=HEADER)
data = user_name.json()
return data["displayName"]
画像加工部分
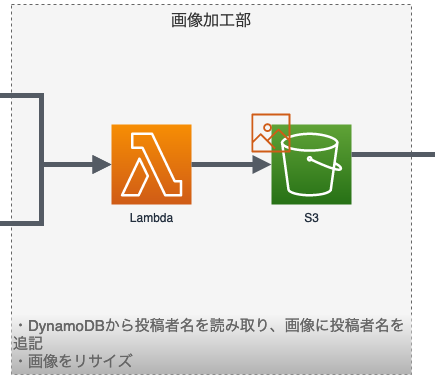
DynamoDBとLambda、S3の組み合わせです。
画像保存部のS3バケットに保管された時のイベントをトリガーにLambdaを動かしています。
LambdaはDynamoDBのデータを読み込んで、画像に投稿者名を追記するのと、画像のリサイズをしています。
このあたりの画像加工はPillowを使っています。
フォントはあんずもじ を使いました。
Lambda内にフォントファイルを配置してます。
Lambdaコード
import os
import sys
import boto3
import logging
from PIL import Image, ImageFont, ImageDraw
# Log設定
LOGGER = logging.getLogger()
LOGGER.setLevel(logging.INFO)
# dynamoDB テーブル名
DYNAMODB_TABLE_NAME = "TABLE_NAME"
# S3 Bucket名
BUCKET_NAME = "BUCKET_NAME"
# フォント設定
FONT = {
"file_path": "font/AP.ttf",
"size": 60,
"color": (10, 12, 16)
}
# 動画サイズ
# FullHD
MOVIE_SIZE = (1920, 1080)
# FullHDの90%(プロジェクタ対応)
# MOVIE_SIZE = (int(1920*0.9), int(1080*0.9))
# 背景色
RGB_BG_COLOR = (30, 30, 30)
RGBA_BG_COLOR = (30, 30, 30, 1)
#main
def lambda_handler(event, context):
LOGGER.info(event)
LOGGER.info(sys.version)
row_bucket_name = event['Records'][0]['s3']['bucket']['name']
key =event['Records'][0]['s3']['object']['key']
s3 = boto3.client('s3')
imagePath = "/tmp/" + os.path.basename(key)
phot_user_name = get_user_name(DYNAMODB_TABLE_NAME, key)
photo_txt = "┸ " + phot_user_name + " 様"
# S3のバケットからファイルをダウンロード
with open(imagePath, 'wb') as data:
s3.download_fileobj(row_bucket_name, key, data)
file_size = os.path.getsize(imagePath)
file_check = os.path.exists(imagePath)
# 文字入れ
tmp_image_name = create_image(imagePath, photo_txt, 20, 20, max_length=740)
# S3のバケットのgrayディレクトリにファイルを保存
s3 = boto3.resource('s3')
upload_result = s3.meta.client.upload_file(tmp_image_name, BUCKET_NAME, key)
LOGGER.info(upload_result)
def get_user_name(dynamodb_table, filename):
dynamoDB = boto3.resource("dynamodb")
table = dynamoDB.Table(DYNAMODB_TABLE_NAME)
get_dynamodb_response = table.get_item(
TableName=dynamodb_table, Key={'filename': filename}
)
LOGGER.info(get_dynamodb_response)
return get_dynamodb_response["Item"]["username"]
def create_image(img_path, text, height, width, max_length=740):
#フレームのベースイメージ 真っ白画像を生成する
video_frame = Image.new('RGBA', MOVIE_SIZE, RGBA_BG_COLOR)
tmp_img_path = img_path + ".tmp.jpeg"
orig_img = Image.open(img_path, 'r')
image = orig_img.copy().convert('RGBA')
imagesize = orig_img.size
minimum_image = image.thumbnail((1700, 956), Image.ANTIALIAS)
LOGGER.info(image)
LOGGER.info(minimum_image)
#画像の中心地点を計算してフレームのベースに合成する
p = (round(((MOVIE_SIZE[0] - image.size[0]) / 2)-230), round((MOVIE_SIZE[1] - image.size[1]) / 2)-20)
video_frame.paste(image, p)
bg = Image.new("RGB", MOVIE_SIZE, RGB_BG_COLOR)
bg.paste(video_frame, mask=video_frame.split()[3])
# テキスト追加
font = ImageFont.truetype(FONT["file_path"], FONT["size"])
draw = ImageDraw.Draw(bg)
font_size = font.getsize(text)
# 画像右下に'Sampleと表示' #FFFは文字色(白)
draw.text((bg.size[0] - font_size[0] - 115, bg.size[1] - font_size[1] - 80), text, FONT["color"], font=font, stroke_width=2, stroke_fill="#EEE")
# ファイルを保存
bg.save(tmp_img_path, 'JPEG', quality=100)
return tmp_img_path
動画生成部分
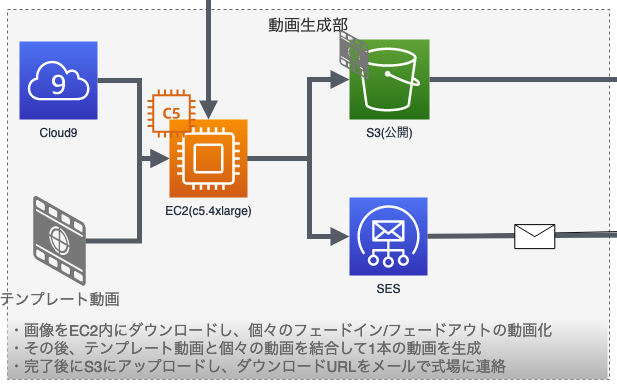
ここが一番苦戦した部分です。
S3とEC2、Cloud9の組み合わせです。
最初はLambdaで作ろうと色々やったんですが、最終的にEC2となりました。
Lambdaでmoviepy…というか標準外のライブラリが簡単に使えるともっと幸せになれたのになーといった感じでした。
今回は動画生成するタイミングは自分でコントロールする必要があったので、コードエディタとしてCloud9を活用しました。
結婚式中に動画生成するため、使える時間も15分程度となるのでEC2もパワーあるインスタンスにし、各画像の動画化をマルチスレッド化して高速化しました。
ffmpegをGPUで動かすのも試したのですが、moviepyのffmpegがうまくGPU使ってくれなかったので断念して、CPUパワーでぶん殴りました。
10スレッドで動かし、100枚程度の画像をフェードイン/フェードアウトする4秒の動画にするのが15分以内で完了しました。力こそ正義ですね。
最終的には、Cloud9からEC2内のスクリプトを実行して、動画を生成。
出来上がった動画をS3にアップロードが完了したタイミングで結婚式場のメールアドレスにダウンロードURLを連絡するという形となりました。
何故か起動後1回目しか動かない謎のトラップが出来上がり、本番ではまるのですが…
コード
import os
import sys
import glob
import boto3
import logging
import datetime
import time
from concurrent.futures import ThreadPoolExecutor
from moviepy.editor import *
from botocore.exceptions import ClientError
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
# Log設定
LOGGER = logging.getLogger()
LOGGER.setLevel(logging.INFO)
# S3 Bucket名
BUCKET_NAME = "BUCKET_NAME"
# S3 Movie upload
UPLOAD_BACKT_NAME = "UPLOAD_BACKT_NAME"
# 動画設定
# サイズ
# 動画サイズ
# FullHD
MOVIE_SIZE = (1920, 1080)
# FPS
FPS = 30
# 仮フォルダ名生成
today = datetime.datetime.today()
TMP_DIR = f"/tmp/{today.strftime('%Y%m%d')}/"
TMP_MOV_DIR = TMP_DIR + "TMP_MOV/"
# 動画生成ワーカー数(本番環境(c5.4xlarge)で10)
WOKER_NUM = 10
# メール
# 送信元
SENDER = "mail@mail.com"
# テスト用宛先
#RECIPIENT = "mail@gmail.com"
# 本番用宛先
RECIPIENT = "mail@mail.com"
CONFIGURATION_SET = "config"
CHARSET = "utf-8"
SUBJECT = "エンドロール動画ダウンロードURLのご連絡"
BODY_TEXT ="2boです。\n以下のURLからダウンロードをお願いいたします。\n\n"
def send_email(_download_url):
sesc = boto3.client("ses")
msg_body_txt = BODY_TEXT + _download_url
msg = MIMEMultipart('mixed')
# Add subject, from and to lines.
msg['Subject'] = SUBJECT
msg['From'] = SENDER
msg['To'] = RECIPIENT
msg_body = MIMEMultipart('alternative')
textpart = MIMEText(msg_body_txt.encode(CHARSET), 'plain', CHARSET)
msg_body.attach(textpart)
msg.attach(msg_body)
print(msg)
try:
#Provide the contents of the email.
response = sesc.send_raw_email(
Source=SENDER,
Destinations=[
RECIPIENT
],
RawMessage={
'Data':msg.as_string(),
},
ConfigurationSetName=CONFIGURATION_SET
)
# Display an error if something goes wrong.
except ClientError as e:
print(e.response['Error']['Message'])
else:
print("Email sent! Message ID:"),
print(response['MessageId'])
def create_movie_parts(local_img_file):
tmp_clips = []
clip = ImageClip(local_img_file).set_duration(4)
clip = clip.crossfadein(1.2)
clip = clip.crossfadeout(1.2)
tmp_clips.append(clip)
file_name = os.path.splitext(os.path.basename(local_img_file))[0]
movie_file_path = TMP_MOV_DIR + file_name + ".mp4"
# スライドショーの動画像を作成する処理
f_tmp_clip = concatenate_videoclips(tmp_clips, method="compose")
f_tmp_clip.write_videofile(
movie_file_path,
fps=FPS,
write_logfile=False,
audio=False,
threads=2,
)
print(movie_file_path)
def main(event):
LOGGER.info(sys.version)
LOGGER.info("呼ばれています")
# フォルダ作成
os.makedirs(TMP_MOV_DIR, exist_ok=True)
# 動画ファイル名
dt_now = datetime.datetime.now()
movie_file_name = dt_now.strftime("%Y%m%d_%H:%M:%S") + ".mp4"
movie_file_path = TMP_DIR + movie_file_name
s3r = boto3.resource("s3")
s3c = boto3.client("s3")
s3_datas = s3r.Bucket(BUCKET_NAME).objects.filter(Prefix=event["type"])
s3_data_list = [k.key for k in s3_datas]
LOGGER.info(s3_data_list)
for img_data in s3_data_list:
LOGGER.info(img_data)
imagePath = TMP_DIR + os.path.basename(img_data)
with open(imagePath, "wb") as data:
s3c.download_fileobj(BUCKET_NAME, img_data, data)
local_img_files = glob.glob(TMP_DIR + "*.jpeg")
with ThreadPoolExecutor(max_workers=WOKER_NUM, thread_name_prefix="thread") as executor:
for m in local_img_files:
print(m)
executor.submit(create_movie_parts, m)
LOGGER.info("submit end")
print("fix tmp movie")
time.sleep(3)
clips = []
tmp_mov_files = glob.glob(TMP_MOV_DIR + "*.mp4")
tmp_mov_files.append("/home/ec2-user/environment/local_scripts/create_movie/endroll.mp4")
for mov_parts in tmp_mov_files:
clip = VideoFileClip(mov_parts)
clips.append(clip)
print(mov_parts)
final_clip = concatenate_videoclips(clips)
final_clip.write_videofile(
movie_file_path,
fps=FPS,
write_logfile=False,
audio=False,
threads=8,
)
# S3 upload
s3r2 = boto3.resource("s3")
mov_parts_file_name = os.path.basename(movie_file_path)
key = "MOVIE/" + mov_parts_file_name
upload_result = s3r2.meta.client.upload_file(
movie_file_path,
UPLOAD_BACKT_NAME,
key,
ExtraArgs={"ContentType": "mp4", "ACL": "public-read"}
)
# send email
download_url = "https://hogehoge.s3-ap-northeast-1.amazonaws.com/" + key
send_email(download_url)
if __name__ == "__main__":
print(datetime.datetime.now())
stratTime = time.time()
print(stratTime)
event = {"type": "wedding"}
main(event)
print(LOGGER)
endTime = time.time() # プログラムの終了時刻
runTime = endTime - stratTime # 処理時間
print(runTime) # 処理時間を表示
print(datetime.datetime.now())
動画公開部分
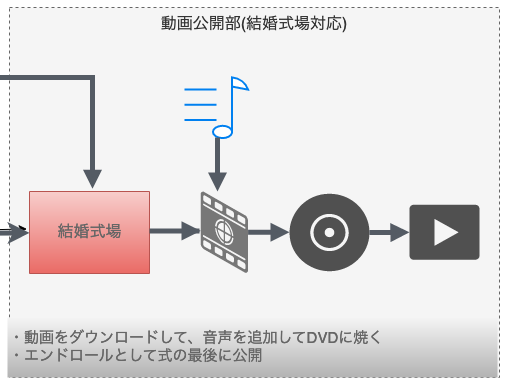
式場にこの仕組をやりたいと話した最初は対応したことないので難しいかも…と言われましたがなんだかんだでうまくやっていただけました。
式場の制限でPCの画面を直接写すことはできない(トラブル防止らしい)と言われたので、メールでダウンロードURLを連絡し、DVDに焼いたり、音楽つけるのをお願いしました。
音楽は式途中に画像枚数から15分くらいになるかも…と連絡しておけば調整してもらえたので助かりました。
音楽つけるとこ含めて、式の前日にリハーサルができたのも助かりました。
臨機応変に対応してもらえる式場でめっちゃ助かりました。
こういった部分は式場の協力が必須なので、コミュニケーション取っておく必要ですね。
その他
LINEのQRコード連絡用紙も妻にデザインしてもらい、コンビニプリントで準備
また、式場にお願いして高砂横にPCを置く場所を用意してもらいました。

本番
朝、式場入してから動画生成までを一人でリハーサルを実施し、 「もしも」を考えて想定しいたインスタンスタイプc5.2xlargeをc5.4xlargeに変更(事前の確認でc5.2xlargeで50枚15分程度だった)
リハーサル結果も問題無かったのでそのまま式を開始(というか他にやること多くてやってられなかった)
予想では写真50枚くらいだろうと思ってたのですが、披露宴前の段階で50枚を超えていたという… 式開始前のオレ、ナイス判断!
エンドロール生成前で最終的に約100枚の画像が送られてきており、当初想定でいってたら完全にアウトだった(参加者に10代、20代がほとんどいないのに…)
しかし、リハーサル後にインスタンスの再起動を忘れており、起動後10分程度でスクリプトがハング。めっちゃ焦ってインスタンス再起動して再実行という非常に胃が痛くなる対応を実施
式場の人の協力でごっとことなきできました。
また、エンドロールが当初5分予定が10分程度となったので式スケジュールも変更となり、最後の方はてんやわんやでしたがなんとか終えることができました。 終わりよければ全てよし!
まとめ
- 仕組みとしては割と簡単に実装できる
- Lambdaは楽だけど、込み入ったことやろうとすると結構めんどくさい
- 機能実装以外に式場の協力が必須なので、実現するにはかなり調整が必要
- 本番トラシューはおすすめしない
- 最後の方の料理の味は覚えてないというか食べれてない
- 今後、結婚式で同じようなことを考える人の参考になれば
- ということで干し芋